








5 cheat sheets to help you get started with Google Cloud
Google Cloud 24.03.2020 
Improved Speech-to-Text models and features now available in new languages
From call analytics to automated video captioning, the Speech interface is changing how people interact and unlocking new business opportunities. After all, speech recognition technology is at the heart of all transformations and brings new ideas.
The Google Cloud Speech-to-Text API allows users to send audio messages in various formats and receive their transcription. And the capabilities of this technology support thousands of different solutions, including Contact Center AI and Video Transcription.
Speech-to-Text is the most accessible, exclusive, and beneficial technology. Therefore, we are pleased to announce to you its updated features, which include:
- seven completely new languages;
- improvement and expansion of telephony to three new languages;
- speech adaptation for 68 new languages;
- diarization of speakers in 10 new languages;
- and automatic punctuation for 18 new languages.
As a result, more than 200,000 users will benefit from Speech-to-Text technology for the first time, and more than 3 billion will receive more accurate and functional transcription.
Support expansion
Since the first announcement of Speech-to-Text, Google has continuously expanded its range of supported languages (up to 127 in total) to provide high-quality speech recognition technology. Now 7 new languages will be available to users: Burmese, Estonian, Uzbek, Punjabi, Albanian, Macedonian and Mongolian
Sourcenext, the maker of the Pocketalk portable voice translator, is an organization that enjoys comprehensive Google Cloud Speech-to-Text language support.

“Google Cloud’s powerful Speech-to-Text capabilities made it possible for us to build our Pocketalk,” said Hajime Kawatake, COO of Technology Strategy, Sourcenext Corporation. “This has improved the quality of our product, as customers can receive highly accurate and reliable translations from anywhere in the world.”
Advanced telephony model
In the spring of 2018, Google launched the Extended US English Telephony Transcription Model, which improved speech recognition and transcription for customers with imperfect phone and video call audio. As a result, the quality level increased by 62% compared to the base model and helped Contact Center AI transform the call center’s work.
We are announcing support for three new languages in Speech-to-Text: English, Russian and Spanish (USA).

One of the first to use this feature was Voximplant, a cloud platform for communication services and application developers with many corporate clients in Russia. They instantly realized the exceptional accuracy of the new model, as evidenced by the words of Alexey Aylarov, CEO of Voximplant:
“We partnered with Google Cloud to upgrade our voice platform with Google AI technology. Because we often receive low-bandwidth phone network audio, advanced telephony models are game-changing, enabling more accurate conversations between people and virtual agents. We are excited about Google Cloud’s commitment to delivering high-quality models to even more users.”
Speech adaptation
Speech adaptation allows users to tune powerful Google models in real-time. With the help of language adaptation, you can recognize names and product names. It is also possible to set the API to return information, which significantly improves the quality of speech recognition.
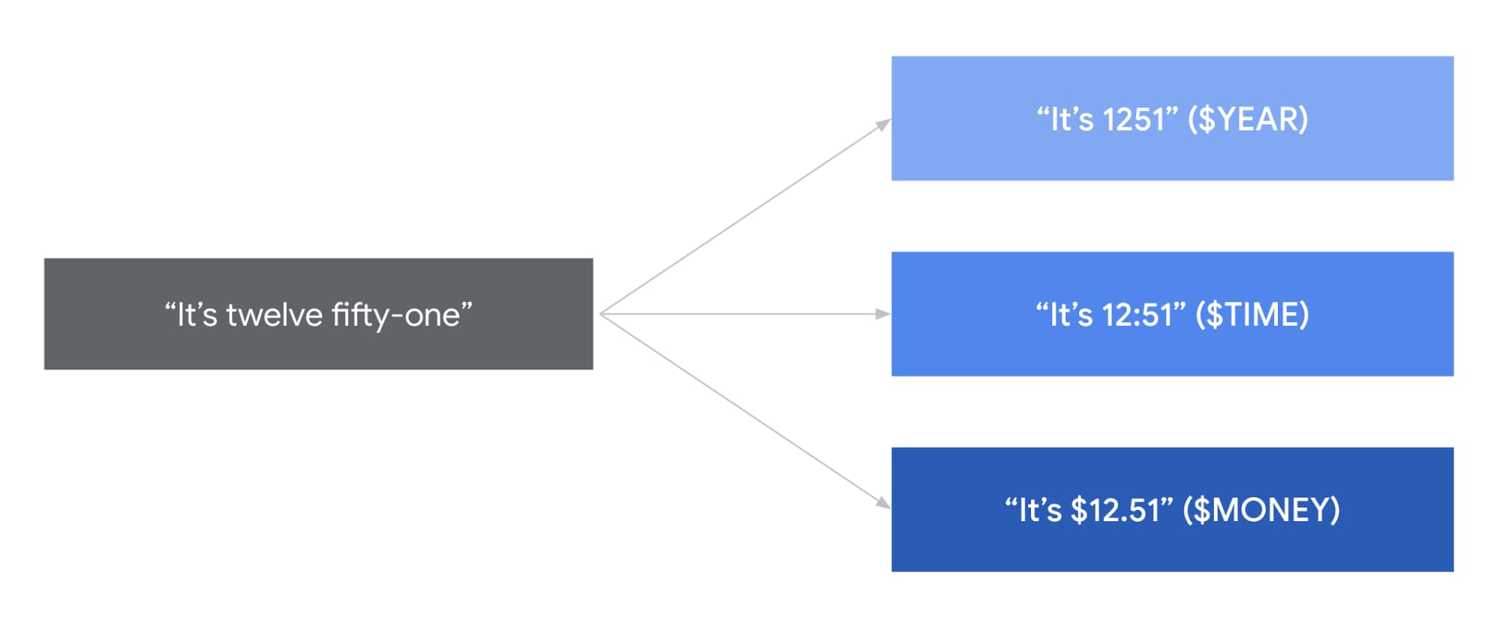
Google is rolling out new technology that improves language adoption in 68 regions. This innovation will allow users to control in detail the influence of the speech model on the most critical terms. In addition, more popular “number classes” are being added in several new languages:
- French
- German
- Spanish
- Japanese
- Mandarin
- and others.
Speaker diarization
Diarization is the ability to automatically identify individual words and sentences from different speakers in an audio file, allowing users to understand what was said and who said it. The ability to easily add subtitles to audio or video files is now available in 10 new languages:
- English (UK)
- Spanish
- Japanese
- Mandarin
- and others.
Automatic punctuation
Punctuation is a crucial factor in improving transcription accuracy and translation quality. Therefore, with the introduction of automatic punctuation in 18 new languages, most users will be able to receive transcripts that accurately reproduce the context that a particular user was trying to convey. Here is a list of languages that this feature has become available in:
- Deutsch
- French
- Japanese
- Swedish
- and others.
So, new languages and improved interface features will allow a billion users worldwide to use high-quality speech recognition technology. If you are interested in transforming your organization with Speech-to-Text technology, contact Cloudfresh! Our certified Google Cloud experts will advise and do everything necessary to ensure that you use existing technologies as efficiently as possible.

Get in touch with Сloudfresh

