


















5 fiches pratiques pour bien démarrer avec Google Cloud
Google Cloud 24.03.2020 
Modèles et fonctionnalités Speech-to-Text améliorés : De nouvelles langues désormais disponibles
De l’analyse d’appels au sous-titrage automatique de vidéos, l’interface Speech transforme nos interactions et ouvre de nouvelles opportunités commerciales. Après tout, la technologie de reconnaissance vocale est au cœur de toutes les transformations et fait émerger de nouvelles idées.
L’API Google Cloud Speech-to-Text permet aux utilisateurs d’envoyer des messages audio sous divers formats et d’en recevoir la transcription. Les capacités de cette technologie soutiennent des milliers de solutions differentes, notamment Contact Center AI et la transcription vidéo.
Speech-to-Text s’impose comme une technologie accessible, exclusive et particulièrement bénéfique. C’est pourquoi nous avons le plaisir de vous annoncer la mise à jour de ses fonctionnalités, qui incluent :
- sept langues totalement inédites ;
- l’amélioration et l’extension de la téléphonie à trois nouvelles langues ;
- l’adaptation vocale pour 68 nouvelles langues ;
- la diarisation des locuteurs dans 10 nouvelles langues ;
- et la ponctuation automatique pour 18 nouvelles langues.
Grâce à ces avancées, plus de 200 000 utilisateurs bénéficieront pour la première fois de la technologie Speech-to-Text, et plus de 3 milliards de personnes profiteront d’une transcription plus précise et fonctionnelle.
Extension de la prise en charge
Depuis l’annonce initiale de Speech-to-Text, Google n’a cessé d’élargir son éventail de langues prises en charge (jusqu’à 127 au total) afin d’offrir une technologie de reconnaissance vocale de haute qualité. Désormais, 7 nouvelles langues sont disponibles : le birman, l’estonien, l’ouzbek, le pendjabi, l’albanais, le macédonien et le mongol.
Sourcenext, le fabricant du traducteur vocal portable Pocketalk, figure parmi les organisations qui tirent pleinement parti de la prise en charge linguistique étendue de Google Cloud Speech-to-Text.

« Les puissantes capacités de Google Cloud Speech-to-Text nous ont permis de concevoir notre Pocketalk », déclare Hajime Kawatake, COO de la stratégie technologique chez Sourcenext Corporation. « Cela a considérablement amélioré la qualité de notre produit, car nos clients peuvent désormais obtenir des traductions d’une grande précision, partout dans le monde. »
Modèle de téléphonie avancé
Au printemps 2018, Google a lancé le modèle étendu de transcription téléphonique pour l’anglais américain, améliorant ainsi la reconnaissance vocale pour les clients confrontés à des qualités audio de réseaux téléphoniques ou d’appels vidéo imparfaites. Résultat : le niveau de qualité a bondi de 62 % par rapport au modèle de base, aidant Contact Center AI à transformer le travail des centres d’appels.
Nous annonçons aujourd’hui la prise en charge de trois nouvelles langues dans Speech-to-Text : l’anglais, le russe et l’espagnol (États-Unis).

Voximplant, une plateforme cloud de services de communication pour développeurs d’applications comptant de nombreux clients entreprises, a été l’une des premières à adopter cette fonctionnalité. Ils ont immédiatement constaté la précision exceptionnelle du nouveau modèle, comme le souligne Alexey Aylarov, PDG de Voximplant :
« Nous nous sommes associés à Google Cloud pour moderniser notre plateforme vocale avec la technologie d’IA de Google. Comme nous traitons souvent de l’audio provenant de réseaux téléphoniques à faible bande passante, les modèles de téléphonie avancés changent la donne. Ils permettent des conversations plus fluides et précises entre les humains et les agents virtuels. Nous saluons l’engagement de Google Cloud à fournir des modèles de haute qualité à un nombre toujours croissant d’utilisateurs. »
Adaptation vocale
L’adaptation vocale permet aux utilisateurs de personnaliser les puissants modèles de Google en temps réel. Grâce à cette adaptation linguistique, vous pouvez reconnaître des noms propres ou des noms de produits spécifiques. Il est également possible de paramétrer l’API pour qu’elle renvoie des informations contextuelles, ce qui améliore nettement la qualité de la reconnaissance.
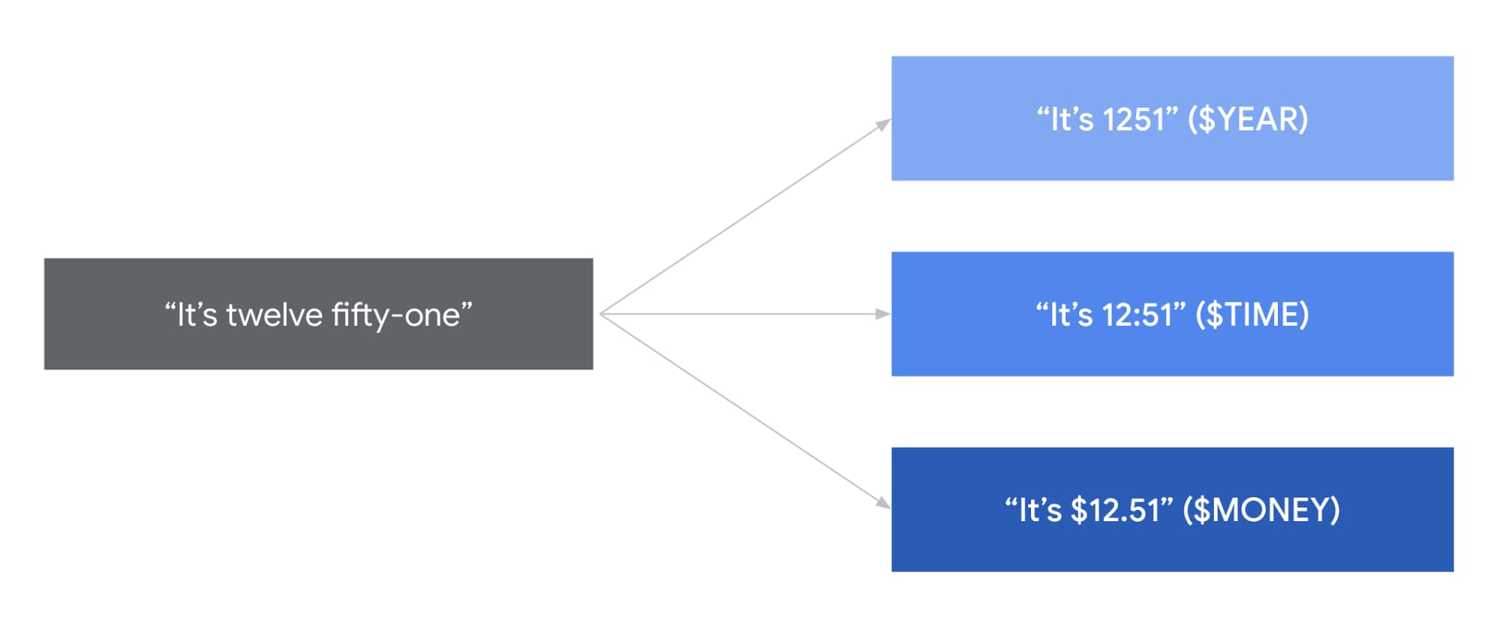
Google déploie actuellement une nouvelle technologie qui optimise l’adaptation linguistique dans 68 régions. Cette innovation permettra aux utilisateurs de contrôler finement l’influence du modèle vocal sur les termes les plus critiques. De plus, des « classes de nombres » populaires sont ajoutées dans plusieurs nouvelles langues :
- Français
- Allemand
- Espagnol
- Japonais
- Mandarin
- et bien d’autres.
Diarisation des locuteurs
La diarisation est la capacité d’identifier automatiquement les mots et les phrases de différents interlocuteurs au sein d’un même fichier audio. Elle permet ainsi de comprendre précisément qui dit quoi. La possibilité d’ajouter facilement des sous-titres aux fichiers audio ou vidéo est désormais disponible dans 10 nouvelles langues :
- Anglais (Royaume-Uni)
- Espagnol
- Japonais
- Mandarin
- et bien d’autres.
Ponctuation automatique
La ponctuation est un facteur déterminant pour accroître la précision de la transcription et la qualité de la traduction. Avec l’introduction de la ponctuation automatique dans 18 nouvelles langues, la majorité des utilisateurs pourront obtenir des transcriptions qui restituent fidèlement le contexte voulu. Voici les langues pour lesquelles cette fonctionnalité est désormais accessible :
- Allemand
- Français
- Japonais
- Suédois
- et bien d’autres.
Ainsi, ces nouvelles langues et l’amélioration des fonctionnalités de l’interface permettront à des milliards d’utilisateurs de profiter d’une reconnaissance vocale de pointe. Si vous souhaitez transformer votre organisation grâce à la technologie Speech-to-Text, contactez Cloudfresh ! Nos experts certifiés Google Cloud vous conseilleront et mettront tout en œuvre pour que vous utilisiez ces technologies le plus efficacement possible.

Contactez Cloudfresh

