


















Welcome to the special Google Cloud Next ’26 blog series
Under the Hood of the AI Hypercomputer: 8th-Gen TPUs & Virgo Network

Concluding our Google Cloud Next ‘26 specials is the hardware. Because none of the AI agents we’ve talked about previously can actually do their jobs without some serious power backing them up.
That’s where the next set of announcements comes in. Google introduced its eighth-generation Tensor Processing Units (TPUs), which power what they are calling the AI Hypercomputer.
These TPUs run on custom Axion Arm-based CPUs and use a fourth-generation liquid cooling setup. The main takeaway here? They are pulling off about twice the performance per watt compared to the last generation.
The TPU 8t: Built for Heavy Training
When it comes to training massive models, the TPU 8t is the answer. Google can link up to 9,600 of these chips together in a single superpod, sharing 2 petabytes of memory and putting out 121 exaflops of compute power. But what actually matters for engineers is efficiency.
The system hits 97% “goodput” because it uses Optical Circuit Switching to automatically route around dead hardware without crashing the job. At the same time, a feature called TPUDirect speeds up storage access by a factor of ten.
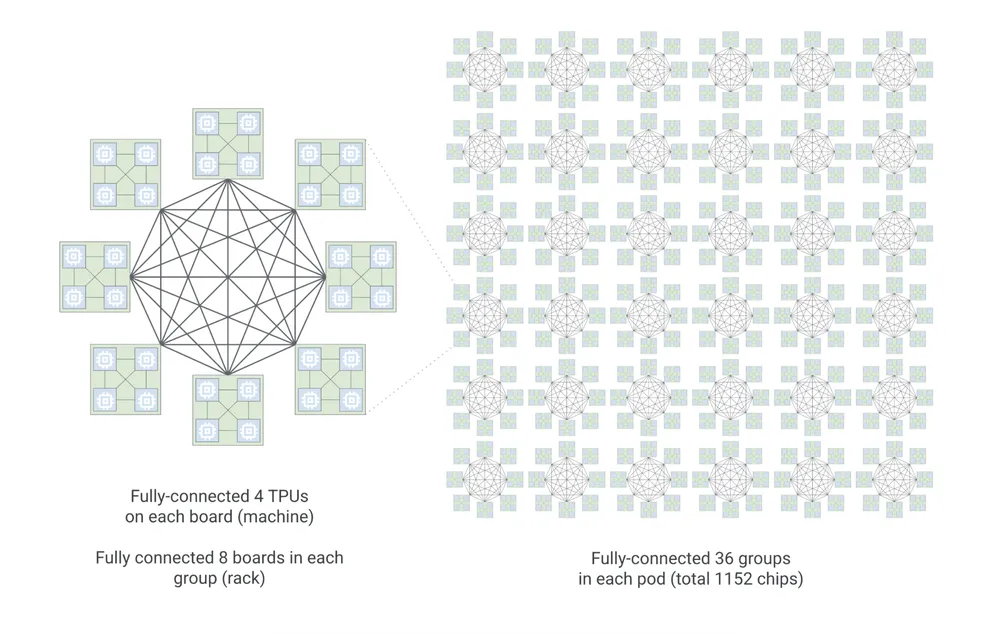
The TPU 8i: Tuned for Live Agents
For actually running the agents day-to-day (inference), Google built the TPU 8i. It’s specifically designed to handle a ton of simultaneous requests. Each pod connects 1,152 TPUs using a new “Boardfly” layout.
To keep memory bottlenecks from slowing things down, they combined 288 GB of high-bandwidth memory with 384 MB of on-chip SRAM, which is three times more than the previous generation.
Factor in the new Collectives Acceleration Engine that cuts down internal latency by five times, and you end up getting roughly 80% better performance for every dollar spent.
That’s exactly why infrastructure matters so much. When it’s not good enough, AI just stays a test project. When done right, however, AI actually becomes part of your business operations.”

The Virgo Network: Wiring the Campus Together
To keep all these chips talking to each other, Google rolled out the Virgo network. It relies on a “campus-as-a-computer” model and treats the entire data center like one giant machine. By flattening the network design into a two-layer setup, they managed to cut base latency by about 40%.
At full scale, Virgo can connect up to 134,000 of those TPU 8t chips at once, pushing 47 petabits of data per second. They also split the architecture logically: one layer handles communication inside the pod, another manages lateral traffic across the data center, and the Jupiter front-end handles the traffic coming in and out.
New Compute Instances to Handle the Load
Finally, to handle the sheer amount of data these agents constantly go through, Google introduced a few new compute instances.
The C4N series can process up to 95 million packets per second, while the memory-heavy M4N series brings in Hyperdisk Extreme and packs 26.57 GB of RAM per vCPU.
On the orchestration side, GKE Agent Sandbox can now instantly spin up 300 secure sandboxes every second within a single cluster. This makes it incredibly easy for teams to run massive, highly parallel workloads without hitting a wall.o
When it comes to deploying scalable processes, the GKE Agent Sandbox is an absolute game-changer. The ability to instantly spin up 300 secure sandboxes per second within a single cluster gives development teams unprecedented freedom.
It makes launching massive, highly parallel AI workloads incredibly simple, with zero latency or security trade-offs.”

Ready to Lay the Foundation for the Agentic Era?
You can design the smartest AI agents in the market, but they will just stall out if your infrastructure lacks the power to run them. To move your AI out of the test phase and into actual production, you need serious hardware to back it up.
As a global Google Cloud Premier Partner, Cloudfresh helps you:
- Deploy the latest TPU architectures to maximize your AI performance and keep your infrastructure costs completely under control.
- Restructure your cloud network to cut base latency and speed up data traffic across your entire environment.
- Move your most demanding operations to the new memory-heavy compute instances to process massive data volumes without performance drops.
- Spin up secure GKE sandboxes to run parallel AI workloads safely and avoid system bottlenecks.
If you want to see how these updates could work out for your particular use cases, we’ve got a personalized trial/demo/workshop/training/audit offer for you. All you have to do is fill out the short form below, and we’ll set it up.
