


















Bienvenue dans notre série d’articles dédiée à Google Cloud Next ’26
Dans les coulisses de l’hypercalculateur IA : TPU de 8e génération et réseau Virgo

Pour conclure nos éditions spéciales sur Google Cloud Next ’26, place au matériel. Car aucun des agents IA dont nous avons parlé précédemment ne peut accomplir sa mission sans une puissance de calcul conséquente pour le soutenir.
C’est ici qu’intervient la nouvelle série d’annonces. Google a présenté ses unités de traitement de tenseurs (TPU) de huitième génération, qui alimentent ce que Google appelle l’Hypercalculateur IA.
Ces TPU fonctionnent sur des processeurs personnalisés Axion basés sur Arm et utilisent un système de refroidissement liquide de quatrième génération. Le résultat clé ? Ils offrent environ deux fois plus de performance par watt par rapport à la génération précédente.
Le TPU 8t : Conçu pour l’entraînement intensif
Lorsqu’il s’agit d’entraîner des modèles massifs, le TPU 8t est la solution. Google peut relier jusqu’à 9 600 de ces puces dans un seul « superpod », partageant 2 pétaoctets de mémoire et atteignant une puissance de calcul de 121 exaflops. Mais pour les ingénieurs, c’est l’efficacité qui prime.
Le système atteint un « goodput » de 97 % grâce à la commutation de circuits optiques (Optical Circuit Switching), qui contourne automatiquement le matériel défaillant sans interrompre le travail. Parallèlement, une fonctionnalité nommée TPUDirect accélère l’accès au stockage jusqu’à 10 fois.
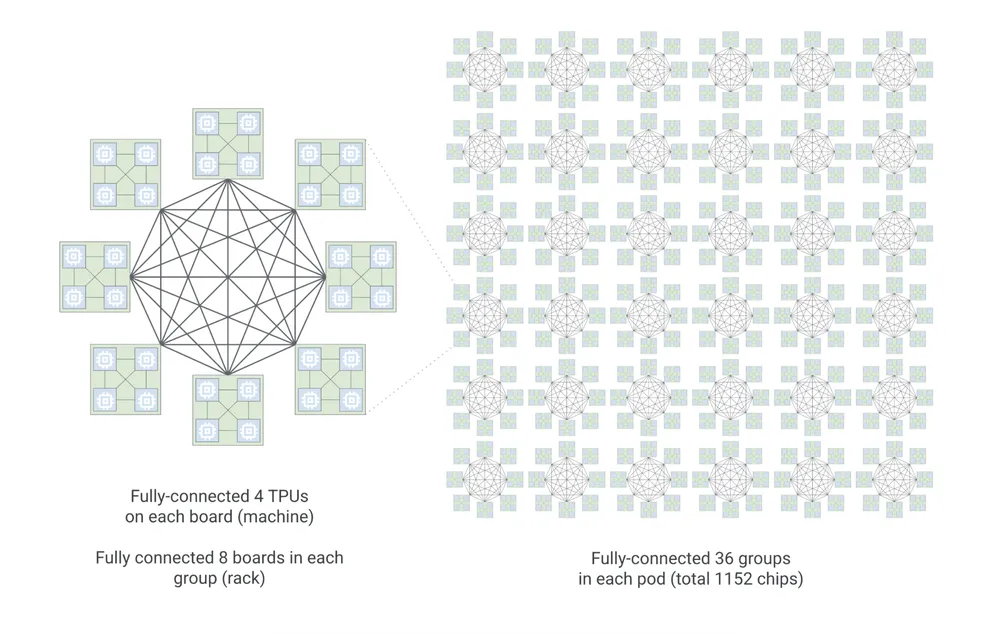
Le TPU 8i : Optimisé pour les agents en direct
Pour faire fonctionner les agents au quotidien (inférence), Google a conçu le TPU 8i. Il est spécifiquement élaboré pour gérer un volume massif de requêtes simultanées. Chaque pod connecte 1 152 TPU via une nouvelle architecture appelée « Boardfly ».
Afin d’éviter que les goulots d’étranglement de la mémoire ne ralentissent les processus, Google a combiné 288 Go de mémoire à haute bande passante avec 384 Mo de SRAM sur puce, soit trois fois plus que la génération précédente.
Ajoutez à cela le nouveau moteur d’accélération Collectives qui réduit la latence interne par cinq, et vous obtenez un rendement environ 80 % supérieur pour chaque dollar investi.
C’est précisément pourquoi l’infrastructure est cruciale. Si elle n’est pas à la hauteur, l’IA reste au stade de projet pilote. Mais lorsqu’elle est performante, l’IA s’intègre pleinement aux opérations de votre entreprise. »

Le réseau Virgo : Relier l’ensemble du campus
Pour permettre à toutes ces puces de communiquer entre elles, Google a déployé le réseau Virgo. Il repose sur un modèle de « campus-ordinateur » et traite l’ensemble du centre de données comme une seule machine géante. En simplifiant la conception du réseau en une structure à deux couches, ils ont réussi à réduire la latence de base d’environ 40 %.
À pleine échelle, Virgo peut connecter jusqu’à 134 000 puces TPU 8t simultanément, transférant 47 pétabits de données par seconde. L’architecture est segmentée de manière logique : une couche gère la communication interne au pod, une autre gère le trafic latéral à travers le centre de données, et le front-end Jupiter gère le trafic entrant et sortant.
Nouvelles instances de calcul pour gérer la charge
Enfin, pour absorber la quantité astronomique de données traitées en permanence par ces agents, Google a lancé plusieurs nouvelles instances de calcul.
La série C4N peut traiter jusqu’à 95 millions de paquets par seconde, tandis que la série M4N, axée sur la mémoire, intègre Hyperdisk Extreme et propose 26,57 Go de RAM par vCPU.
Côté orchestration, GKE Agent Sandbox permet désormais de lancer instantanément 300 environnements sécurisés sécurisés par seconde au sein d’un seul cluster. Cela facilite considérablement l’exécution de charges de travail massives et hautement parallèles sans rencontrer d’obstacles techniques.
Pour permettre à toutes ces puces de communiquer entre elles, Google a déployé le réseau Virgo. Il repose sur un modèle de « campus-ordinateur » et traite l’ensemble du centre de données comme une seule machine géante. En simplifiant la conception du réseau en une structure à deux couches, ils ont réussi à réduire la latence de base d’environ 40 %.
À pleine échelle, Virgo peut connecter jusqu’à 134 000 puces TPU 8t simultanément, transférant 47 pétabits de données par seconde. L’architecture est segmentée de manière logique : une couche gère la communication interne au pod, une autre gère le trafic latéral à travers le centre de données, et le front-end Jupiter gère le trafic entrant et sortant.
Les TPU apportent la puissance de calcul, Virgo élimine les goulets d’étranglement réseau, et GKE Agent Sandbox rend l’ensemble exploitable dans de véritables environnements de production.
Lorsqu’il s’agit de déployer des processus IA évolutifs, GKE Agent Sandbox change véritablement la donne. La capacité à lancer instantanément jusqu’à 300 sandboxes sécurisées par seconde au sein d’un même cluster offre aux équipes de développement une liberté sans précédent.
Cela rend le déploiement de charges de travail IA massives et hautement parallèles extrêmement simple, sans compromis ni sur les performances, ni sur la sécurité. »

Prêt à poser les bases de l’ère agentique ?
Vous pouvez concevoir les agents d’IA les plus avancés du marché ; sans une infrastructure suffisamment puissante pour les faire fonctionner, ils resteront limités.
Pour faire passer votre IA du stade expérimental à une véritable exploitation en production, vous avez besoin d’une infrastructure matérielle à la hauteur.
En tant que Partenaire Premier Google Cloud mondial, Cloudfresh vous aide à :
- Déployer les dernières architectures TPU afin de maximiser les performances IA tout en gardant vos coûts d’infrastructure sous contrôle.
- Repenser votre réseau cloud afin de réduire la latence et accélérer les flux de données dans l’ensemble de votre environnement.
- Migrer vos charges les plus exigeantes vers les nouvelles instances haute mémoire afin de traiter d’immenses volumes de données sans perte de performance.
- Déployer des environnements GKE Sandbox sécurisés afin d’exécuter des workloads IA parallèles en toute sécurité et sans créer de goulets d’étranglement.
Si vous souhaitez découvrir comment ces évolutions peuvent s’appliquer à vos cas d’usage spécifiques, nous proposons des offres personnalisées : essais, démonstrations, ateliers, formations ou audits. Il vous suffit de remplir le formulaire ci-dessous et nous organiserons cela avec vous.
