


















Vítejte u speciální série článků ke Google Cloud Next ’26
Pod kapotou AI hyperpočítače: 8. generace TPU a síť Virgo

Náš seriál o novinkách z Google Cloud Next ‘26 uzavíráme pohledem na hardware. Žádný z AI agentů, o kterých jsme psali dříve, totiž nemůže odvádět svou práci bez pořádného výkonu v zádech.
Právě proto přichází další vlna oznámení. Google představil osmou generaci procesorů Tensor Processing Units (TPU), které pohánějí to, co nazývá „AI Hypercomputer“.
Tato TPU běží na zakázkových CPU Axion postavených na architektuře Arm a využívají čtvrtou generaci kapalinového chlazení. Hlavní přínos? Ve srovnání s předchozí generací dosahují přibližně dvojnásobného výkonu na watt.
TPU 8t: Navrženo pro náročný trénink
Když jde o trénování masivních modelů, řešením je TPU 8t. Google dokáže propojit až 9 600 těchto čipů do jediného superpodu, který sdílí 2 petabajty paměti a disponuje výpočetním výkonem 121 exaflops. Pro inženýry je však klíčová především efektivita.
Systém dosahuje 97% „goodputu“, protože využívá optické přepínání obvodů (Optical Circuit Switching) k automatickému obcházení nefunkčního hardwaru, aniž by došlo k pádu celého procesu. Funkce TPUDirect navíc desetinásobně zrychluje přístup k úložišti.
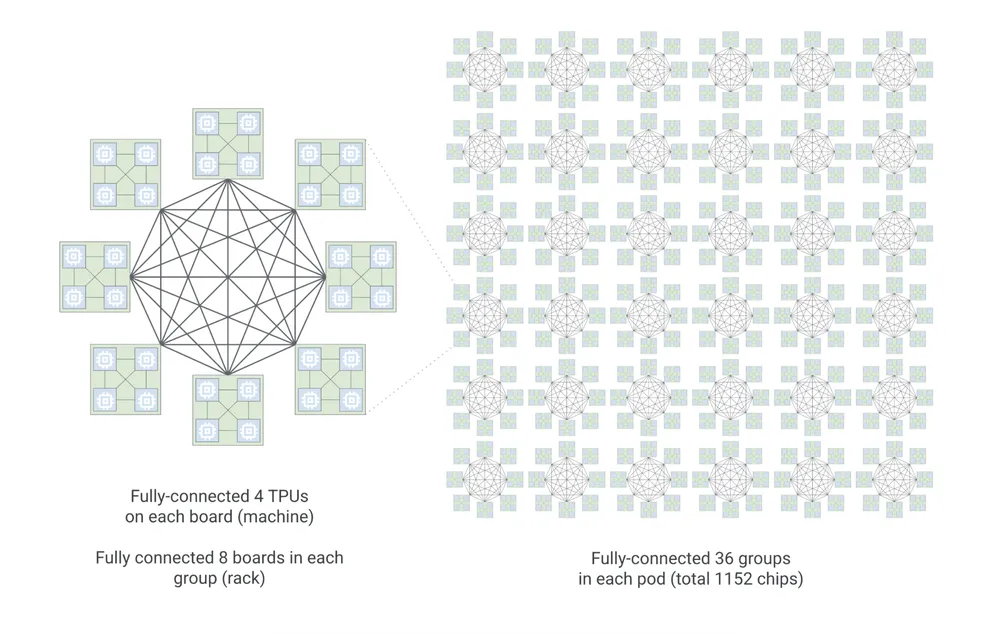
TPU 8i: Vyladěno pro agenty v reálném čase
Pro každodenní provoz agentů (inferenci) vyvinul Google TPU 8i. Je navrženo speciálně pro zvládání obrovského množství současných požadavků. Každý pod propojuje 1 152 jednotek TPU pomocí nového uspořádání „Boardfly“.
Aby úzká hrdla v paměti nezpomalovala provoz, zkombinovali vývojáři 288 GB paměti s vysokou propustností s 384 MB on-chip SRAM — což je třikrát více než u předchozí generace.
Když k tomu připočtete nový akcelerátor Collectives Acceleration Engine, který pětkrát snižuje interní latenci, získáte zhruba o 80 % lepší výkon na každý vynaložený dolar.
Právě proto na infrastruktuře tolik záleží. Pokud není dostatečně kvalitní, AI zůstane jen testovacím projektem. Když se to ale udělá správně, stane se AI plnohodnotnou součástí vašich obchodních operací.”

Síť Virgo: Propojení celého kampusu
Aby spolu všechny tyto čipy mohly komunikovat, nasadil Google síť Virgo. Ta staví na modelu „campus-as-a-computer“ a zachází s celým datovým centrem jako s jedním obřím strojem. Díky zjednodušení síťového designu na dvouvrstvé uspořádání se podařilo snížit základní latenci o 40 %.
V plném rozsahu dokáže Virgo propojit až 134 000 čipů TPU 8t najednou a přenášet 47 petabitů dat za sekundu. Architektura je logicky rozdělena: jedna vrstva řeší komunikaci uvnitř podu, druhá spravuje laterální provoz napříč datovým centrem a front-end Jupiter se stará o příchozí a odchozí provoz.
Nové výpočetní instance pro vysokou zátěž
A konečně, aby bylo možné zpracovat obrovské množství dat, kterými agenti neustále procházejí, představil Google několik nových výpočetních instancí.
Řada C4N dokáže zpracovat až 95 milionů paketů za sekundu, zatímco řada M4N s velkou kapacitou paměti přináší Hyperdisk Extreme a nabízí 26,57 GB RAM na vCPU.
V oblasti orchestrace dokáže GKE Agent Sandbox v rámci jednoho clusteru okamžitě spustit 300 zabezpečených sandboxů každou sekundu. To týmům neuvěřitelně usnadňuje spouštění masivních, vysoce paralelních úloh bez jakýchkoli omezení.
Pokud jde o nasazování škálovatelných procesů, GKE Agent Sandbox naprosto mění pravidla hry. Možnost okamžitě spustit 300 bezpečných sandboxů za sekundu v rámci jediného clusteru dává vývojářským týmům nevídanou svobodu.
Díky tomu je spouštění masivních, vysoce paralelních AI úloh neuvěřitelně jednoduché, bez jakýchkoli kompromisů v oblasti latence nebo bezpečnosti.”

Jste připraveni položit základy pro éru agentů?
Můžete navrhnout ty nejchytřejší AI agenty na trhu, ale pokud vaše infrastruktura nebude mít dostatek výkonu k jejich spuštění, nikam se neposunete. K přesunu vaší AI z testovací fáze do ostré produkce potřebujete silný hardware.
Jako globální Google Cloud Premier Partner vám Cloudfresh pomůže:
- Nasadit nejnovější architektury TPU pro maximalizaci výkonu AI při zachování plné kontroly nad náklady na infrastrukturu.
- Restrukturalizovat vaši cloudovou síť pro snížení základní latence a zrychlení datového provozu v celém prostředí.
- Přesunout nejnáročnější operace na nové výpočetní instance s vysokou pamětí pro zpracování masivních objemů dat bez propadů výkonu.
- Spustit bezpečné sandboxy GKE pro bezpečný paralelní běh AI úloh a zamezení úzkým hrdlům v systému.
Pokud chcete vidět, jak by tyto novinky mohly fungovat ve vašich konkrétních případech, máme pro vás nabídku personalizovaného trialu, dema, workshopu, školení nebo auditu. Stačí vyplnit krátký formulář níže a my vše připravíme.
