


















Приветствуем в специальной серии статей по Google Cloud Next ’26
Под капотом ИИ-гиперкомпьютера: TPU 8-го поколения и сеть Virgo

Завершаем серию материалов о Google Cloud Next ’26 обзором аппаратных решений. Ведь ни один ИИ-агент, о которых мы говорили ранее, не сможет выполнять свои задачи без мощной инфраструктурной поддержки.
Для решения Google представил тензорные процессоры (TPU) восьмого поколения, которые формируют основу концепции AI Hypercomputer.
Эти TPU работают на базе кастомных процессоров Axion (архитектура Arm) и используют систему жидкостного охлаждения четвертого поколения. Ключевой результат: они обеспечивают примерно двукратный прирост производительности на ватт по сравнению с предыдущей итерацией.
TPU 8t: Решение для высоконагруженного обучения
Когда речь идет об обучении массивных моделей, оптимальным выбором становятся TPU 8t. Google объединяет до 9 600 таких чипов в единый суперпод, обеспечивая общий объем памяти в 2 петабайта и вычислительную мощность в 121 эксафлопс. Однако для инженеров критически важна именно эффективность.
Система достигает показателя полезной пропускной способности в 97% благодаря использованию Optical Circuit Switching — технологии, которая автоматически перенаправляет трафик в обход вышедших из строя компонентов без остановки рабочих процессов. Параллельно с этим функционал TPUDirect ускоряет доступ к хранилищу в десять раз.
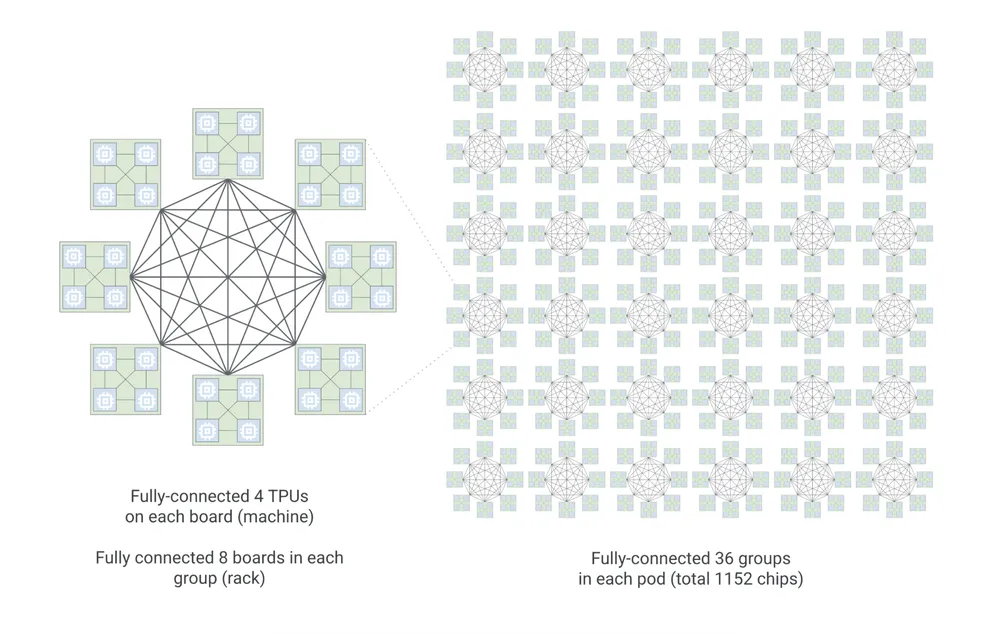
TPU 8i: Оптимизация для работы агентов в реальном времени
Для повседневного инференса и эксплуатации агентов Google разработал TPU 8i. Эта архитектура спроектирована специально для обработки огромного количества одновременных запросов. Каждый под объединяет 1 152 TPU с использованием новой топологии Boardfly.
Чтобы исключить задержки из-за пропускной способности памяти, инженеры скомбинировали 288 ГБ высокоскоростной памяти (HBM) с 384 МБ встроенной в чип SRAM, что в три раза превышает показатели прошлого поколения.
Учитывая новый Collectives Acceleration Engine, который в пять раз снижает внутренние задержки, бизнес получает примерно на 80% больше производительности на каждый инвестированный доллар.
Именно поэтому инфраструктура имеет решающее значение. При недостаточном уровне мощностей AI остается лишь экспериментальным проектом. При правильном подходе он становится неотъемлемой частью ваших бизнес-операций.»

Сеть Virgo: Синхронизация кампуса
Для обеспечения бесперебойной коммуникации между чипами Google развернул сеть Virgo. Она базируется на модели «campus-as-a-computer» и рассматривает весь дата-центр как одну масштабную вычислительную единицу. За счет упрощения дизайна сети до двухуровневой структуры удалось снизить базовую задержку примерно на 40%.
При полной масштабируемости Virgo позволяет объединять до 134 000 чипов TPU 8t одновременно, обеспечивая пропускную способность в 47 петабит данных в секунду. Архитектура логически разделена: один уровень отвечает за коммуникации внутри пода, другой управляет горизонтальным трафиком в дата-центре, а фронтенд Jupiter контролирует входящие и исходящие потоки.
Новые инстансы Compute Engine для обработки нагрузок
Наконец, для обработки колоссальных объемов данных, с которыми постоянно взаимодействуют агенты, Google представил новые типы вычислительных инстансов.
Серия C4N способна обрабатывать до 95 миллионов пакетов в секунду, а серия M4N с увеличенным объемом памяти поддерживает Hyperdisk Extreme и предлагает 26,57 ГБ RAM на каждый vCPU.
В части оркестрации GKE Agent Sandbox теперь позволяет мгновенно развертывать по 300 защищенных песочниц в секунду внутри одного кластера. Это значительно упрощает запуск масштабных параллельных воркфлоу без риска столкнуться с инфраструктурными ограничениями.
Когда речь идет о развертывании масштабируемых процессов, GKE Agent Sandbox полностью меняет правила игры. Возможность мгновенно запускать по 300 безопасных песочниц в секунду внутри одного кластера дает командам разработки беспрецедентную свободу.
Это делает запуск масштабных, высокопараллельных AI-воркфлоу невероятно простым, без задержек и компромиссов в вопросах безопасности.»

Готовы заложить фундамент для эры агентов?
Вы можете спроектировать самых умных ИИ-агентов на рынке, но они окажутся бесполезными, если вашей инфраструктуре не хватит мощности для их работы. Чтобы вывести ИИ из фазы тестирования в реальный продакшн, необходима серьезная аппаратная поддержка.
Как глобальный Google Cloud Premier Partner, Cloudfresh помогают вам:
- Внедрять новейшие архитектуры TPU для максимизации производительности ИИ и контроля затрат на инфраструктуру.
- Реструктурировать облачную сеть для минимизации задержек и ускорения трафика данных во всей среде.
- Переносить наиболее ресурсоемкие операции на новые вычислительные инстансы с большим объемом памяти для обработки массивов данных без потери скорости.
- Развертывать безопасные песочницы GKE для параллельного запуска ИИ-воркфлоу без риска создания узких мест в системе.
Если вы хотите увидеть, как эти обновления могут быть применены в ваших конкретных кейсах, у нас есть предложение по проведению триала, демо, воркшопа или аудита. Просто заполните форму ниже, и мы все организуем.
