


















Witamy w specjalnym cyklu artykułów poświęconym Google Cloud Next ’26
Co kryje w sobie AI Hypercomputer: Ósma generacja układów TPU i sieć Virgo

Naszą serię poświęconą Google Cloud Next ‘26 kończymy spojrzeniem na sprzęt. Ponieważ żaden z agentów AI, o których wcześniej wspominaliśmy, nie jest w stanie wykonywać swoich zadań bez solidnego zaplecza technicznego.
Właśnie tutaj pojawiają się kolejne ogłoszenia. Google zaprezentowało ósmą generację jednostek Tensor Processing Units (TPU), które napędzają system określany mianem AI Hypercomputer.
Układy TPU bazują na niestandardowych procesorach Axion (architektura Arm) i wykorzystują czwartą generację systemu chłodzenia cieczą. Najważniejszy wniosek? Zapewniają one niemal dwukrotnie wyższą wydajność na wat w porównaniu z poprzednią generacją.
TPU 8t: Stworzone do najbardziej wymagających treningów
Jeśli chodzi o trenowanie potężnych modeli, TPU 8t jest bezkonkurencyjne. Google może połączyć do 9600 takich chipów w ramach jednego superpoda, współdzieląc 2 petabajty pamięci i generując 121 eksaflopsów mocy obliczeniowej. Jednak tym, co naprawdę liczy się dla inżynierów, jest efektywność.
System osiąga 97% wskaźnika „goodput”, ponieważ wykorzystuje technologię Optical Circuit Switching do automatycznego omijania awaryjnych modułów bez przerywania pracy. Jednocześnie funkcja TPUDirect dziesięciokrotnie przyspiesza dostęp do pamięci masowej.
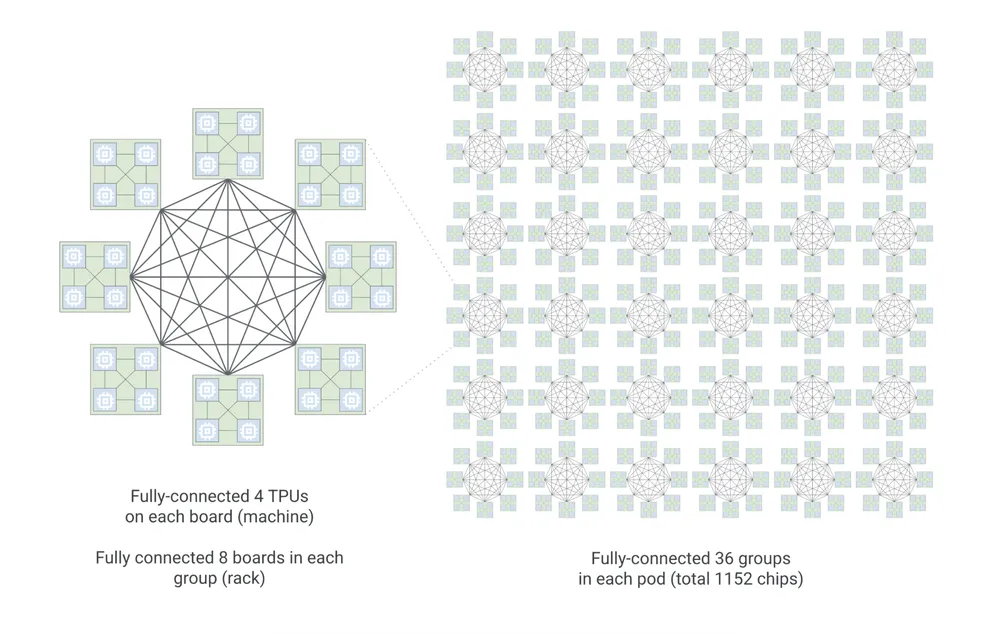
TPU 8i: Zoptymalizowane pod kątem aktywnych agentów
Do codziennego działania agentów (inferencji) Google stworzyło układ TPU 8i. Został zaprojektowany specjalnie z myślą o obsłudze ogromnej liczby jednoczesnych żądań. Każdy moduł łączy 1152 procesory TPU dzięki nowemu układowi „Boardfly”.
Aby uniknąć wąskich gardeł w pamięci, połączono 288 GB pamięci o wysokiej przepustowości z 384 MB wbudowanej pamięci SRAM — to trzy razy więcej niż w poprzedniej generacji.
Dodajmy do tego nowy silnik Collectives Acceleration Engine, który pięciokrotnie redukuje wewnętrzne opóźnienia, a w efekcie otrzymujemy o około 80% lepszy stosunek wydajności do każdego wydanego dolara.
Właśnie dlatego infrastruktura ma tak kluczowe znaczenie. Gdy jest niewystarczająca, AI pozostaje jedynie projektem testowym. Jednak zrobiona dobrze sprawia, że sztuczna inteligencja staje się integralną częścią operacji biznesowych.”

Sieć Virgo: Łącząc zasoby w jeden organizm
Aby zapewnić płynną komunikację między tymi wszystkimi układami, Google wprowadziło sieć Virgo. Opiera się ona na modelu „campus-as-a-computer” i traktuje całe centrum danych jak jedną gigantyczną maszynę. Dzięki uproszczeniu architektury sieci do układu dwuwarstwowego udało się obniżyć opóźnienia bazowe o około 40%.
W pełnej skali Virgo może połączyć do 134 000 układów TPU 8t jednocześnie, przesyłając 47 petabitów danych na sekundę. Architektura została podzielona logicznie: jedna warstwa obsługuje komunikację wewnątrz poda, druga zarządza ruchem bocznym w centrum danych, a interfejs Jupiter odpowiada za ruch przychodzący i wychodzący.
Nowe instancje obliczeniowe gotowe na obciążenia
Na koniec, aby poradzić sobie z czystą masą danych przetwarzanych nieustannie przez agentów, Google zaprezentowało kilka nowych instancji obliczeniowych.
Seria C4N może przetwarzać do 95 milionów pakietów na sekundę, podczas gdy bogata w pamięć seria M4N oferuje technologię Hyperdisk Extreme i zapewnia 26,57 GB pamięci RAM na każdy vCPU.
W kwestii orkiestracji, GKE Agent Sandbox pozwala teraz na błyskawiczne uruchamianie 300 bezpiecznych piaskownic na sekundę w ramach jednego klastra. Dzięki temu zespoły mogą z niezwykłą łatwością obsługiwać ogromne, wysoce równoległe zadania bez obaw o limity wydajności.
Jeśli chodzi o wdrażanie skalowalnych procesów, GKE Agent Sandbox całkowicie zmienia zasady gry. Możliwość błyskawicznego uruchomienia 300 bezpiecznych piaskownic na sekundę w ramach jednego klastra daje zespołom deweloperskim niespotykaną swobodę.
Dzięki temu uruchamianie masowych, wysoce równoległych obciążeń AI staje się niezwykle proste, przy zerowych opóźnieniach i bez kompromisów w zakresie bezpieczeństwa.”

Chcesz położyć fundament pod erę agentów?
Możesz zaprojektować najmądrzejszych agentów AI na rynku, ale nie ruszą oni z miejsca, jeśli infrastruktura nie zapewni im mocy. Aby przenieść projekty AI z fazy testowej do realnej produkcji, potrzebujesz solidnego zaplecza sprzętowego.
Jako globalny Google Cloud Premier Partner, Cloudfresh pomaga Ci:
- Wdrażać najnowsze architektury TPU, aby zmaksymalizować wydajność AI i utrzymać koszty infrastruktury pod pełną kontrolą.
- Przebudować sieć chmurową, aby zredukować opóźnienia i przyspieszyć ruch danych w całym środowisku.
- Przenieść najbardziej wymagające operacje do nowych instancji obliczeniowych o dużej pojemności pamięci, by przetwarzać masowe ilości danych bez spadku wydajności.
- Uruchamiać bezpieczne piaskownice GKE, aby bezpiecznie prowadzić równoległe obciążenia AI i unikać wąskich gardeł systemowych.
Jeśli chcesz zobaczyć, jak te aktualizacje sprawdzą się w Twoich konkretnych przypadkach, mamy dla Ciebie spersonalizowaną ofertę na demo, warsztaty, szkolenie lub audyt. Wystarczy wypełnić krótki formularz, a my zajmiemy się resztą.
