


















Вітаємо у спеціальній серії статей про Google Cloud Next ’26
Під капотом ШІ-гіперкомп’ютера: 8-ме покоління TPU та мережа Virgo

Завершуємо серію спецвипусків про Google Cloud Next ’26 оглядом апаратного забезпечення. Адже жоден з ШІ-агентів, про яких ми говорили раніше, не зможе виконувати свої завдання без серйозних потужностей.
Отже, Google представив восьме покоління тензорних процесорів (TPU), які забезпечують роботу рішення, що вони називають AI Hypercomputer.
Ці TPU працюють на кастомних CPU Axion на базі Arm і використовують систему рідинного охолодження четвертого покоління. Головний результат? Вони забезпечують приблизно вдвічі вищу продуктивність на ват порівняно з попереднім поколінням.
TPU 8t: Створено для важкого навчання
Коли йдеться про тренування масивних моделей, TPU 8t — це оптимальне рішення. Google може об’єднувати до 9 600 таких чипів в один superpod, спільно використовуючи 2 петабайти пам’яті та видаючи 121 ексафлопс обчислювальної потужності. Проте для інженерів справжнє значення має ефективність.
Система досягає 97% корисної пропускної здатності, оскільки використовує Optical Circuit Switching для автоматичного обходу несправного обладнання без зупинки всього процесу. Водночас функція TPUDirect у десять разів прискорює доступ до сховища.
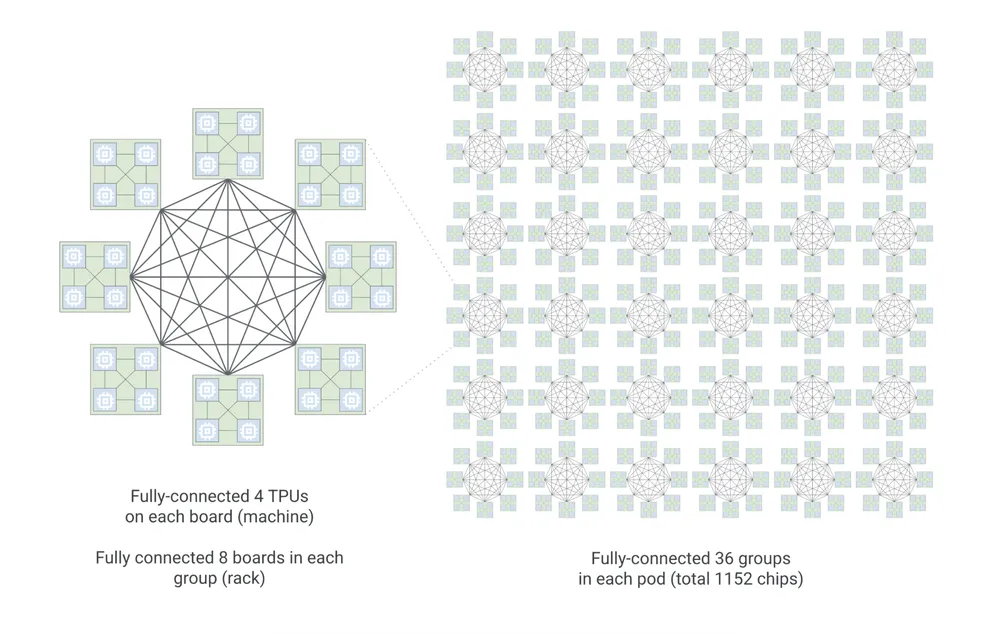
TPU 8i: Оптимізовано для активних агентів
Для безпосереднього запуску агентів (інференсу) Google розробив TPU 8i. Він спеціально спроектований для обробки величезної кількості одночасних запитів. Кожен pod об’єднує 1 152 TPU за допомогою нової топології «Boardfly».
Аби вузькі місця пам’яті не сповільнювали роботу, розробники поєднали 288 ГБ високої пропускної здатності з 384 МБ SRAM, що втричі більше, ніж у попередньому поколінні.
Додайте до цього новий Collectives Acceleration Engine, який у п’ять разів знижує внутрішню затримку, і ви отримаєте приблизно на 80% кращу продуктивність за кожен витрачений долар.
І саме тому інфраструктура є ключовим фактором: вона визначає, чи залишиться AI експериментом, чи стане частиною операційної моделі бізнесу.»

Мережа Virgo: Об’єднання кампусу в єдине ціле
Аби забезпечити стабільну комунікацію між усіма цими чипами, Google запустив мережу Virgo. Вона базується на моделі «кампус як комп’ютер» і розглядає весь дата-центр як одну гігантську машину. Завдяки спрощенню архітектури мережі до дворівневої структури, вдалося знизити базову затримку приблизно на 40%.
На повному масштабі Virgo може одночасно з’єднувати до 134 000 чипів TPU 8t, пропускаючи 47 петабітів даних на секунду. Архітектуру також логічно розділили: один рівень відповідає за комунікацію всередині pod, інший — керує латеральним трафіком по всьому дата-центру, а фронтенд Jupiter обробляє вхідний і вихідний трафік.
Нові інстанси Compute Engine для високих навантажень
Нарешті, для обробки колосальних обсягів даних, через які постійно проходять агенти, Google представив декілька нових інстансів.
Серія C4N здатна обробляти до 95 мільйонів пакетів на секунду, тоді як серія M4N з великим обсягом пам’яті використовує Hyperdisk Extreme і пропонує 26,57 ГБ RAM на кожен vCPU.
З боку оркестрації, GKE Agent Sandbox тепер може миттєво розгортати 300 захищених сендбоксів щосекунди в межах одного кластера. Це дозволяє командам неймовірно легко запускати масивні, високопаралельні воркфлоу без жодних обмежень.
Коли йдеться про розгортання масштабованих процесів, GKE Agent Sandbox — це справжній game-changer. Можливість миттєво запускати до 300 безпечних пісочниць на секунду в межах одного кластера дає командам розробки безпрецедентну свободу.
Це робить запуск масивних паралельних робочих навантажень за використанням ШІ неймовірно простим, без жодних компромісів щодо затримки чи безпеки.»

Готові закласти фундамент для ери агентів?
Ви можете спроєктувати найрозумніших ШІ-агентів на ринку, але вони будуть неефективними, якщо інфраструктурі забракне потужності для їхньої роботи. Аби вивести ШІ з фази тестування в реальний продакшн, потрібна серйозна апаратна підтримка.
Як глобальний Google Cloud Premier Partner, Cloudfresh допомагають вам:
- Розгортати новітні архітектури TPU для максимізації продуктивності ШІ та повного контролю над витратами на інфраструктуру.
- Реструктуризувати хмарну мережу для зниження затримки та пришвидшення трафіку даних у всьому середовищі.
- Переносити найбільш ресурсомісткі операції на нові інстанси з великим обсягом пам’яті для обробки масивів даних без втрати продуктивності.
- Запускати безпечні пісочниці GKE для паралельного виконання ШІ-ворклоудів без ризику виникнення системних затримок.
Якщо ви хочете побачити, як ці оновлення працюватимуть для ваших конкретних кейсів, ми маємо персоналізовану пропозицію на тріал, демо, воркшоп чи аудит. Просто заповніть коротку форму нижче, і ми все організуємо.
