

















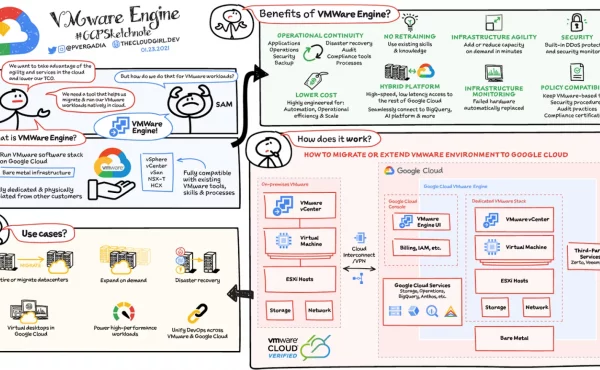
5 шпаргалок, які допоможуть вам при роботі з Google Cloud
Google Cloud 24.03.2020 
Вдосконалені моделі та функції Speech-to-Text тепер доступні новими мовами
Від аналізу викликів до автоматизованих відеосубтитрів — інтерфейс Speech змінює спосіб взаємодії людей та відкриває нові можливості для бізнесу. Адже технологія розпізнавання мови лежить в основі всіх перетворень й втілює нові ідеї в життя.
Google Cloud Speech-to-Text API дозволяє користувачам відправляти аудіоповідомлення різних форматів й отримувати їх транскрипцію. А можливості цієї технології підтримують тисячі різних рішень, включаючи Contact Center AI та Video Transcription.
Speech-to-Text є максимально доступною, ексклюзивною та надзвичайно корисною технологією. Тому ми раді анонсувати вам її оновлені функції, які включають:
- сім абсолютно нових мов;
- удосконалення та розширення телефонії до трьох нових мов;
- адаптація мовлення для 68 нових мов;
- діарізація спікерів у 10 нових мовах (Відокремлення різних голосів в аудіозаписі);
- та автоматична пунктуація для 18 нових мов.
Завдяки цьому, більш ніж 200 тисяч користувачів зможуть скористатися технологією Speech-to-Text вперше, а понад 3 мільярдів отримають більш точну та функціональну транскрипцію.
Розширення підтримки
З моменту першого анонсу Speech-to-Text, Google постійно розширює спектр підтримуваних мов (до 127 в загальній кількості) для забезпечення високоякісної технології розпізнавання мовлення. Зараз користувачам стануть доступні 7 нових мов: бірманська, естонська, узбецька, пенджабська, албанська, македонська і монгольська.

Sourcenext, виробник портативного голосового перекладача Pocketalk, є однією з організацій, що користується всебічною мовною підтримкою Google Cloud Speech-to-Text.
«Широкі можливості Google Cloud Speech-to-Text, уможливили створення нашого Pocketalk», — сказав Хаджиме Каватаке, операційний директор з технологічної стратегії, Sourcenext Corporation. «Завдяки чому — підвищилась якість нашого продукту, оскільки клієнти можуть отримувати високоточні й надійні переклади з будь-якої точки світу».
Удосконалена модель телефонії
Навесні 2018 року Google запустив розширену модель транскрипції телефонії для англійської мови (США), що підвищило рівень розпізнавання мови та транскрипції для клієнтів з неідеальними аудіоданими телефонів та відеодзвінків. Завдяки цьому рівень якості виріс на 62%, у порівнянні з базовою моделлю, та допоміг Contact Center AI трансформувати роботу call-центру.
Тож оголошуємо про підтримку трьох нових мов у Speech-to-Text: англійської, російської й іспанської (США).

Одним з перших, хто скористався цією функцією став Voximplant — хмарна платформа для розробників комунікаційних сервісів і додатків, з багатьма корпоративними клієнтами в Росії. Вони миттєво усвідомили виняткову точність нової моделі, про що свідчать слова Олексія Айларова, Генерального директора Voximplant:
«Ми почали співпрацювати з Google Cloud, тому що хотіли оновити нашу голосову платформу за допомогою технології Google AI. Оскільки ми часто отримуємо аудіосигнали телефонних мереж з низькою пропускною здатністю, вдосконалені моделі телефонії змінюють правила гри, забезпечуючи підвищену точність розмов між людьми і віртуальними агентами. Ми в захваті від прагнення Google Cloud, щодо надання високоякісних моделей ще більшій кількості користувачів».
Адаптація мовлення
Адаптація мови дозволяє користувачам налаштовувати потужні моделі Google в режимі реального часу. За допомогою мовної адаптації можна зробити розпізнавання власних імен та назв продуктів.Також є можливість задати API шляхи повернення інформації, що значно покращує якість розпізнавання мови.
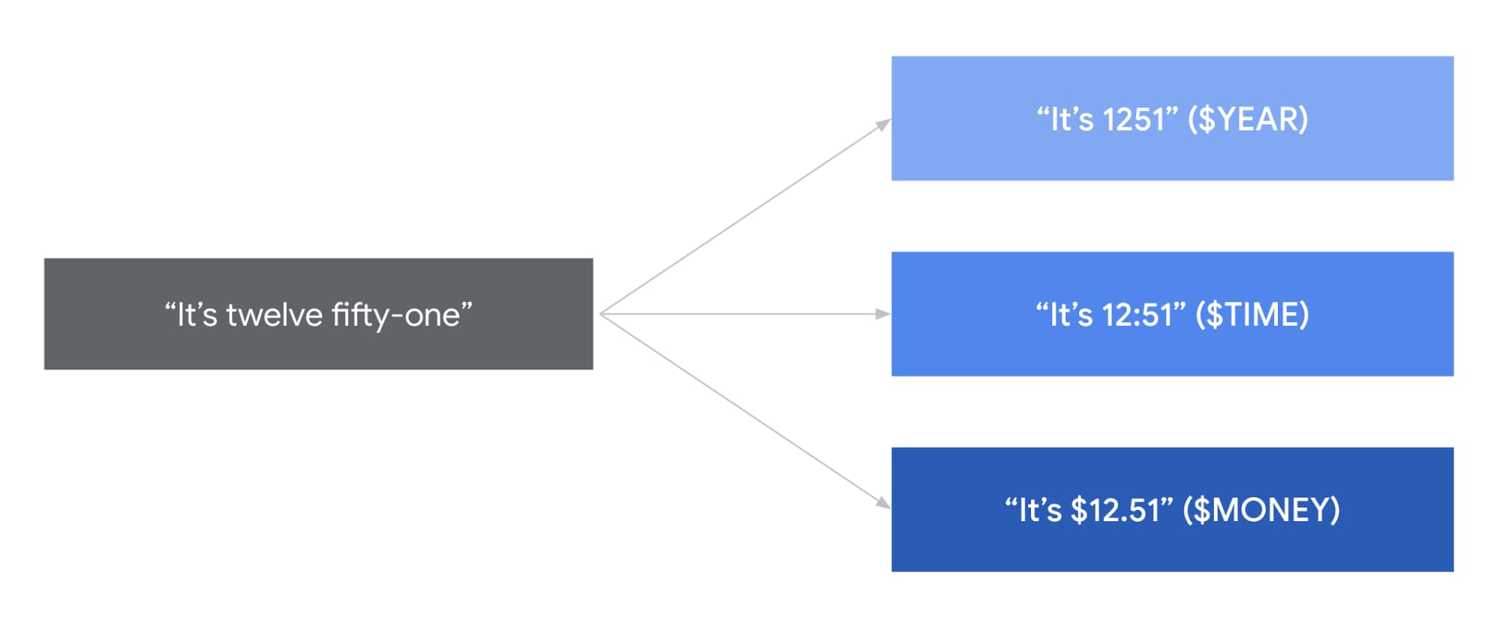 Google впроваджує нову технологію, що поліпшує мовну адаптацію у 68 нових регіонах. Це нововведення дасть можливість користувачам детально контролювати вплив мовленнєвої моделі на найважливіші терміни. Окрім цього, додається велика кількість популярних “числових класів” на декількох нових мовах:
Google впроваджує нову технологію, що поліпшує мовну адаптацію у 68 нових регіонах. Це нововведення дасть можливість користувачам детально контролювати вплив мовленнєвої моделі на найважливіші терміни. Окрім цього, додається велика кількість популярних “числових класів” на декількох нових мовах:
- Французькій
- Німецькій
- Іспанській
- Японській
- Мандаринській
та інших.
Діарізація спікерів
Діарізація — це можливість автоматично визначати окремі слова й речення різних спікерів в аудіофайлі, що дозволяє користувачам зрозуміти не тільки те, що було сказано, але й хто сказав. Можливість з легкістю додавати субтитри до аудіо- або відеофайлів стала доступна в 10 нових мовах:
- Англійській (UK)
- Іспанській
- Японській
- Мандаринській
та інших.
Автоматична пунктуація
Пунктуація являється ключовим фактором, що дозволяє підвищити точність транскрипції та якість перекладу. Тому завдяки впровадженню автоматичної пунктуації у 18 нових мовах, більшість користувачів зможуть отримувати стенограми, що в точності будуть відтворювати контекст, який намагався передати певний користувач. Ось перелік мов, яким стала доступні ця функція :
- Німецька
- Французька
- Японська
- Шведська
та інші.
Отже, нові мови та вдосконаленні функції інтерфейсу дадуть змогу мільярду користувачів по всьому використовувати високоякісну технологію розпізнавання мови. Якщо Ви зацікавленні у трансформації своєї організації за допомогою технології Speech-to-Text — звертайтесь у Cloudfresh! Наші сертифіковані експерти з Google Cloud проконсультують та зроблять все необхідне для того, щоб Ви використовували існуючі технології максимально ефективно.

Зв'яжіться з Сloudfresh

